This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction XML stands for Extensible Markup Language and is one of the more popular formats in which data is stored and shared between systems and software. XML is a versatile coding language similar to HTML. For most third-party applications it is easier to store, search, edit, and retrieve information from XML documents.
Often, small businesses and projects face a shortage of resources, and skilled labor to set up a complex database management system. In this blog, I’ll discuss how to use google sheets as a database and the various methods available! Then, we need to know the tools/options to add, remove or update the database.
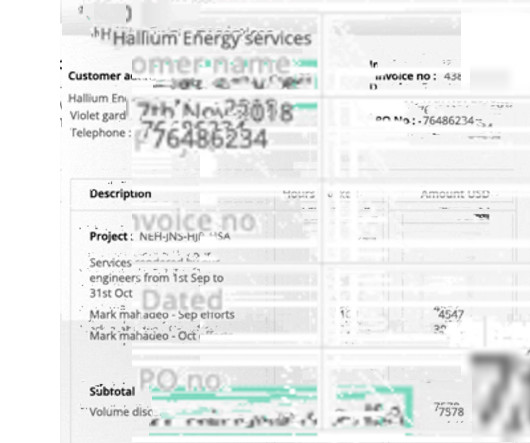
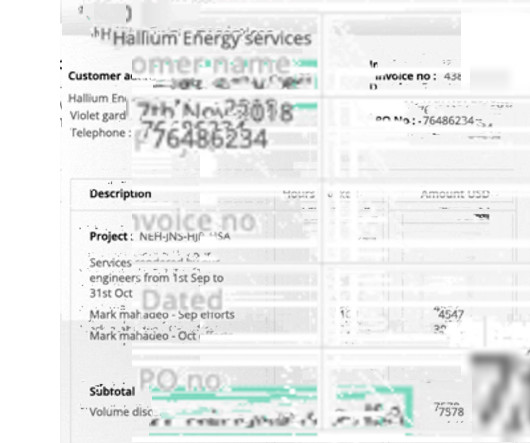
Businesses struggle to organize & identify large numbers of PDF files in their database. Looking to convert bank statements or other documents from PDF to Excel or PDF to XML ? Original file vs renamed file PDF files are convenient for sharing and storing vast amounts of data/information. But PDF file names are not standardized.
Get Started Schedule a Demo Nanonets Documentation If you’re looking to train your own OCR models to build a PDF to database or PDF to table converter, check out the Nanonets API. Need an AI-based online OCR to convert PDF to XML or PDF to database entries , extract data from PDF , extract text from image , or extract text from PDF ?
The following lead generation methods are classified as cold outreach strategies: Purchasing a database : Some organizations specialize in collecting and maintaining business databases. They usually maintain records for multiple contacts within an organization, and you can purchase this database depending on your requirements.
Manual entry of data from these statements into the central database is time-consuming and error-prone. Nanonets’ PDF scraper OCR is particularly useful for converting bank statements into machine-readable structured data formats such as excel files (CVS, XML, JSON etc.).
This could be an Excel spreadsheet, Word document, or even a database. This data can be uploaded into databases or saved as XLSX, CSV, TXT, or any other required format. BeautifulSoup allows you to parse HTML and XML documents. Save the extracted data in the target location. Looking to scrape data from websites?
Instead of storing them as images, it is wise to use PDF OCR to convert them into a searchable database. Other free document conversion tools Looking for something else? Nanonets is one platform suited to converting JPG images to Word files on a large scale.
Export clean structured data as XLS, CSV, or XML etc. or push data into your CRM, WMS, or database directly. Extract text or data accurately with advanced AI-powered OCR extractors that don’t rely on predefined templates. Why convert images to text?
BeautifulSoup allows you to parse HTML and XML documents. Pandas allow storing and manipulating data in various formats, including CSV, Excel, JSON, and SQL databases. Exporting the data to a database of your choice - You can export the extracted data to Google Sheets, Excel, Sharepoint, CRM, or any other database you choose.
Form automation is typically achieved using specialized software tools that automate the data entry process by extracting data from various sources, such as existing databases or spreadsheets. Lack of integration : Manual data entry can be challenging to integrate with other systems, such as databases or CRMs.
By structured, we mean that it has been arranged in columns and rows so it can be easily imported into another program or database. Data extraction can refer to scraping information from web pages or emails but includes any other type of text-based file such as spreadsheets (Excel), documents (Word), XML , PDFs, etc.
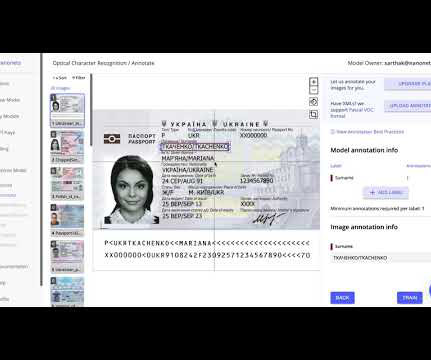
It is necessary for them to build a database of resumes. The resume parser software analyzes resumes, extracts the required information, and allows the information to go into a database with a unique entry for each resume. xls), JSON, or XML. In a year, a company may be receiving thousands of resumes from aspiring candidates.
It is necessary for them to build a database of resumes. The resume parser software analyzes resumes, extracts the required information, and allows the information to go into a database with a unique entry for each resume. xls), JSON, or XML. In a year, a company may be receiving thousands of resumes from aspiring candidates.
JSON, XML, CSV) for further editing or integration with other systems One of Nanonets's standout features is its scalability. Export data from scanned documents to your CRM, WMS, or database in various formats including XLS, CSV, or XML for offline use. While Nanonets is highly accurate, it could be better.
Custom Data actions There is a dedicated section on “custom data actions” which powers all kinds of formatting actions in-house, such as lookup against external databases, finding and replacing characters, etc. The default options include Excel, CSVs, XML and JSON files.
Post Processing: In this step, the extracted data is converted into the required format such as CSV, XML, JSON etc, Also, additional user-defined rules are added on top of the predictions made by AI. Cool Post-processing Features: Assume that your database has been integrated with the the nanonets model.
Advanced AI systems can cross-check claim details against policy data, third-party databases, and historical claim records to detect anomalies and assess the validity of claims. Integrations: Automation pulls data from multiple sources, databases, third-party tools, etc., thus allowing for seamless verification.
You can capture data in almost any format, including tables, text, JSON, or XML. You can export it as JSON, XML, orcustom formats. You can also integrate your OCR system with databases to validate extracted data. Nanonets will analyze these samples to understand the structure of your documents. After that, it costs $0.3
By structured, we mean that it has been arranged in columns and rows so it can be easily imported into another program or database. Data extraction can refer to scraping information from web pages or emails but includes any other type of text-based file such as spreadsheets (Excel), documents (Word), XML , PDFs, etc.
Open banking and API integrations Efficient bank statement processing relies heavily on integrating financial systems such as accounting software, ERP platforms, and databases. 💡 Key benefit : ML fraud detection systems improve risk management and reduce potential financial losses by up to 70%.
Validation and Verification: Extracted data is now checked for accuracy, it could involve multiple options such as: Cross-referencing with existing databases Automated error detection based on predefined logic Confidence scoring for extracted data Manual review 6. Structured data output (JSON, XML, CSV, etc.)
AI-enabled accounts payable software like Nanonets can extract accounts payable data from various sources and convert them into structured digital information that can be further processed or fed into ERPs or databases. and databases (MySQL, PostGres, MSSQL, etc.) There is no standard structure or function to accounts payable software.
doc), HTML XML Data PDF EDI (EDIFACT) and CSV. The data thus read is stored in easy-to-access applications such as a spreadsheet or a database. Optical These are free form texts such as contracts, letters, articles, and memos that may double as invoices in some unstructured, small businesses.
Using the Get Data method The 'Get Data' feature is an MS Excel feature introduced in Excel 2016 that allows you to import data from various sources, including other Excel files, PDFs, JSON, XML, SQL databases, and more. another Excel file, CSV, or database).
Managing multiple invoice formats: Large organizations handle purchase orders and invoices from various sources in diverse formats such as word documents, spreadsheets, XML documents for EDI, PDFs, images, and paper documents. Invoices and POs can also be imported into Nanonets from your mail, apps and databases.
The API uses complex XML payloads and has strict formatting, so while it might initially seem nice to have a high level of detail in every API call, it can quickly become cumbersome for cases where you need to integrate the APIs at some level of scale. <soapenv:Envelope import sqlite3 conn = sqlite3.connect('netsuite_data.db')
Make a digital archive of your financial documents to create a searchable database. They can export data to Excel, CSV, JSON, and XML, integrate with Google Sheets, and access numerous other integrations. This flexibility allows finance professionals to address their unique document processing needs effectively.
AI-driven tools can quickly compare the order information against your database to confirm the accuracy and check for discrepancies. Nanonets supports multiple output formats, including JSON, XML, CSV, and direct API calls to other systems. Automated systems often come with configurable approval workflows.
Want to scrape data from PDF documents, convert PDF to XML or automate table extraction ? Check out Nanonets' PDF scraper or PDF parser to convert PDFs to database entries! Companies can utilize automated systems for customer service, communication between employees, file sharing and collaboration on projects, etc.
You can also set up database matching to verify extracted information against existing patient records, billing systems, or insurance databases. You can also download the structured outputs (CSV, JSON, XML) for further analysis or use webhooks or Zapier to push the data to other systems in real time.
Exports to multiple formats (Excel, CSV, JSON, XML) 7. Parsing data means automatically extracting specific information (like invoice numbers, dates, amounts) from documents and converting it into structured, usable formats that can be used in other systems like spreadsheets or databases. Supports table extraction and formatting 4.
accounting tools (Quickbooks, Xero), CRMs, and databases—no coding required. 💡 Nanonets processes documents up to 80% faster than traditional template-based systems, making it ideal for high-volume workflows. With easy-to-set-up API integrations , Nanonets seamlessly connects with major ERP software (Sage, Netsuite, SAP, etc.),
Export options: Integrates with CRMs, WMS, databases, or exports as XLS/CSV/XML. Fast processing: Reduces time per page from minutes to seconds. Cost savings: Cuts 30%+ on manual processing costs. Scalable: Processes thousands of documents and automates workflows without increasing team size.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content